There are some excellent explanations for these terms including this and this. Essentially, consider the example of information retrieval systems where you have a query which tries to map to the best results. In order to do so, there are certain descriptors or keys which you test against the query, the best of which will have its value selected and shown at the top of the search results. In the context of transformers,
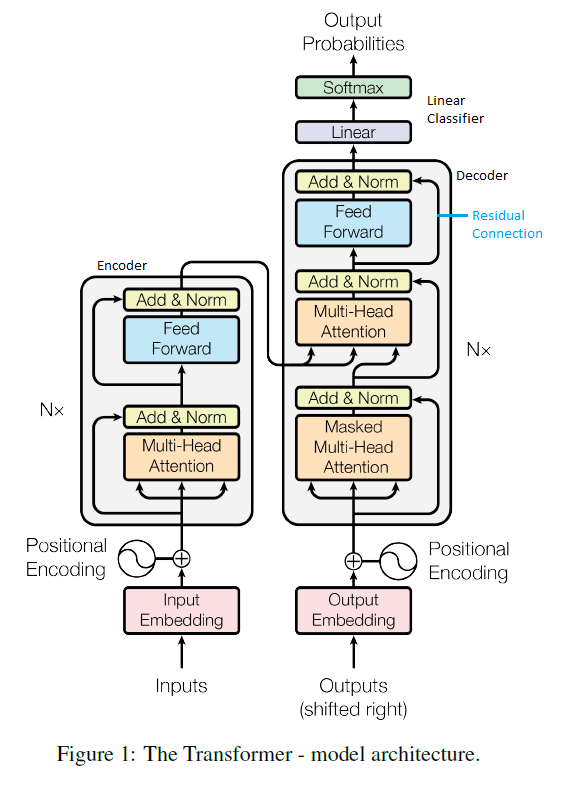
Like RNNs, the transformer model is divided into an encoder and decoder section. The encoder has one set of inputs and the decoder has two sets of inputs(these will be described soon). The set of inputs that the encoder receives is simply the set of inputs that goes into the model(i.e. if you're trying to translate English to French, the inputs into the encoder will be whatever English sentence is fed into the model). Prior to being fed into the encoder, each word in the sentence will be mapped to a vector which represents their relative locations in a high-dimensional space(i.e. the vectors for dog and horse might be relatively similar to one another b/c they are animals). This embedding space/mapping can either be trained or taken from elsewhere. After each word in the sentence is mapped to a vector, they are then added to a positional vector which encapsulates information about the relative location of each word using sine and cosine functions. Then, the encoder takes the resultant vector which represents each word and attempts to spit out new vectors which represent each word's semantic relation(within the sentence as opposed to general meaning like in the embedding stage) to one another. It does this using a combination of multi-headed attention, residual connections, and a feedforward network.
The decoder model is a bit more complex. Let's asume that we are doing English to French translation and we have predicted the first French word. We now want to predict the next word. We will again apply and add embedding(except for French) and positional encoding vectors with regards to the French word. We will then put this vector through 2 attention blocks. The first attention block will use a technique called masking(which I do not completely understand yet). The second attention block will take the results of the first attention block along with the results from the encoder and form assosciation vectors between the French and English words. These resultant association vectors will then go through the rest of the model and output a set of probabilities for the possible selections for the next potential word